SQLite Interface¶
Log analysis in lnav can be done using the SQLite interface. Log messages can be accessed via virtual tables that are created for each file format. The tables have the same name as the log format and each message is its own row in the table. For example, given the following log message from an Apache access log:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
These columns would be available for its row in the access_log table:
log_line |
log_part |
log_time |
log_idle_msecs |
log_level |
log_mark |
log_comment |
log_tags |
log_filters |
c_ip |
cs_method |
cs_referer |
cs_uri_query |
cs_uri_stem |
cs_user_agent |
cs_username |
cs_version |
sc_bytes |
sc_status |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
0 |
<NULL> |
2000-10-10 13:55:36.000 |
0 |
info |
1 |
<NULL> |
<NULL> |
<NULL> |
127.0.0.1 |
GET |
<NULL> |
<NULL> |
/apache_pb.gif |
<NULL> |
frank |
HTTP/1.0 |
2326 |
200 |
Note
Some columns are hidden by default to reduce the amount of noise in
results, but they can still be accessed when explicitly used. The hidden
columns are: log_path, log_text, log_body, and
log_raw_text.
You can activate the SQL prompt by pressing the ; key. At the prompt, you can start typing in the desired SQL statement and/or double-tap TAB to activate auto-completion. A help window will appear above the prompt to guide you in the usage of SQL keywords and functions.
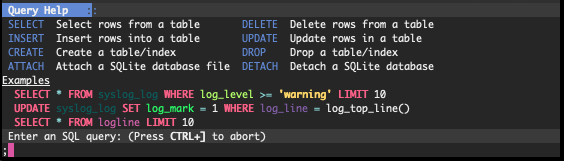
Screenshot of the online help for the SQL prompt.¶
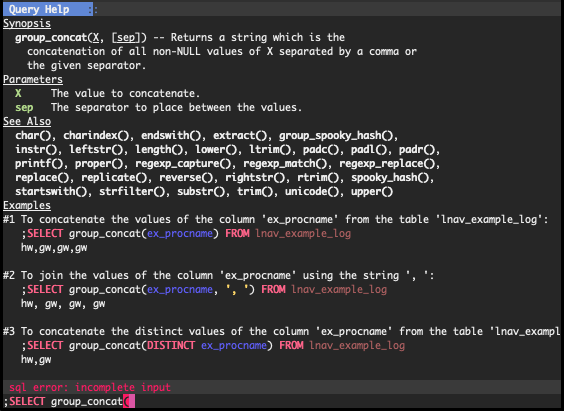
Screenshot of the online help for the group_concat() function.¶
A simple query to perform on an Apache access log might be to get the average and maximum number of bytes returned by the server, grouped by IP address:
;SELECT c_ip, avg(sc_bytes), max(sc_bytes) FROM access_log GROUP BY c_ip
Note
For reference, the PRQL query would look like this:
from access_log | stats.by c_ip {average sc_bytes, max sc_bytes}
After pressing Enter, SQLite will execute the query using lnav’s
virtual table implementation to extract the data directly from the log files.
Once the query has finished, the main window will switch to the DB view to
show the results. Press q to return to the log view and press v
to return to the log view. If the SQL results contain a
log_line column, you can press to Shift + V to
switch between the DB view and the log
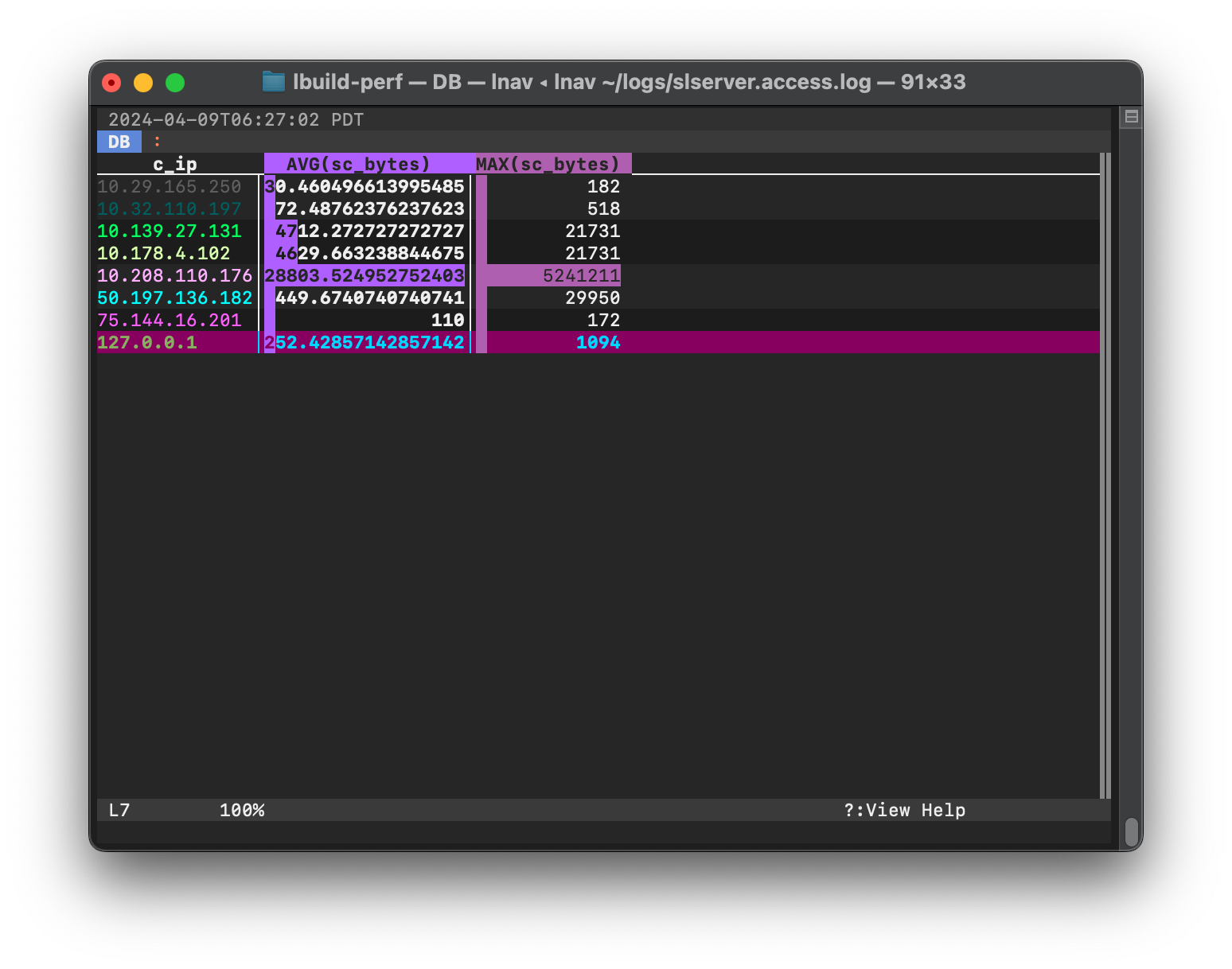
Screenshot of the SQL results view.¶
DB View¶
The DB view has the following display features:
Column headers stick to the top of the view when scrolling.
Numeric columns contain a bar chart of the values.
Pressing p opens an overlay with the columns and the values from the focused row in a vertical orientation for easier reading. Columns with JSON objects/arrays are pretty-printed with bar-charts for numeric values as well. The display will show the value and JSON-Pointer path that can be passed to the jget function.
With the overlay open, pressing CTRL-] will focus into it. Then, you can select a column and copy its contents by pressing c or hide/show it by pressing the space bar. You can also hide/show a column by clicking on the diamond on the left side.
Table cells can be styled by adding a
__lnav_style__column to the query. This column must be a JSON object with the key columns that contains the the column names to be styled and the style configuration. For example, to apply semantic coloring to thecs_uri_stemcolumn you would use the following JSON:{ "columns": { "cs_uri_stem": { "color": "semantic()" } } }
style¶
type
object
properties
text-align
/text-align
How to align text within a cell
type
string
enum
start, center, end
color
/color
The foreground color value for this style. The value can be the name of an xterm color, the hexadecimal value, or a theme variable reference.
type
string
examples
#fff
Green
$black
background-color
/background-color
The background color value for this style. The value can be the name of an xterm color, the hexadecimal value, or a theme variable reference.
type
string
examples
#2d2a2e
Green
underline
/underline
Indicates that the text should be underlined.
type
boolean
bold
/bold
Indicates that the text should be bolded.
type
boolean
italic
/italic
Indicates that the text should be italicized.
type
boolean
strike
/strike
Indicates that the text should be struck.
type
boolean
nestable
/nestable
This highlight can be nested in another highlight.
type
boolean
additionalProperties
False
PRQL Support (v0.12.1+)¶
PRQL is an alternative database query language that compiles to SQLite. You can enter PRQL in the database query prompt and lnav will switch accordingly. A major advantage of using PRQL is that lnav can show previews of the results of the pipeline stages and provide better tab completion options.
A PRQL query starts with the from keyword that specifies the table
to use as a data source. The next stage of a pipeline is started by
entering a pipe symbol (|) followed by a
PRQL transform.
As you build the query in the prompt, lnav will display any relevant
help and preview for the current and previous stages of the pipeline.
The following is a screenshot of lnav viewing a web access log with a query in progress:
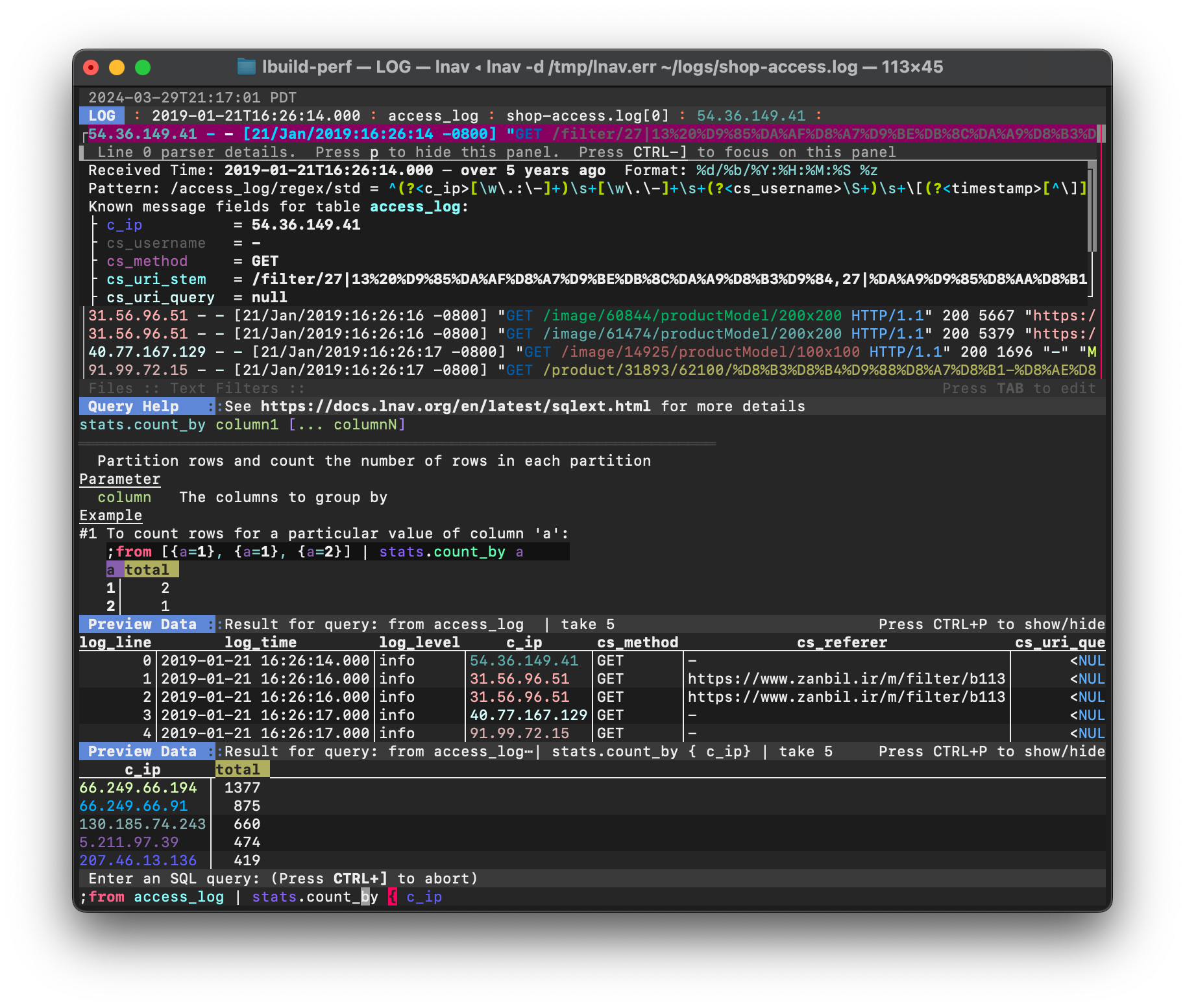
Screenshot of a PRQL query in progress¶
The top half of the window is the usual log message view. Below that is
the online help panel showing the documentation for the stats.count_by
PRQL function. lnav will show the help for what is currently under the
cursor. The next panel shows the preview data for the pipeline stage
that precedes the stage where the cursor is. In this case, the
results of from access_log, which is the contents of the access
log table. The second preview window shows the result of the
pipeline stage where the cursor is located.
Log Tables¶
Each log format has its own database table that can be used to access log
messages that match that format. The table name is the same as the format
name, for example, the syslog_log format will have a table that is
also named syslog_log. There is also an all_logs table
that provides access to all messages from all formats.
Note
Only the displayed log messages are reflected in the SQLite interface. Any log messages that have been filtered out are not accessible.
The columns in the log tables are made up of several builtins along with
the values captured by the log format specification. Use the .schema
command in the SQL prompt to examine a dump of the current database schema.
Note
Unless explicitly stated, builtin columns are read-only and cannot
be changed by an UPDATE.
The following columns are builtin and included in a SELECT *:
- log_line:
The line number for the message in the log view.
- log_time:
The adjusted timestamp for the log message. This time can differ from the log message’s time stamp if it arrived out-of-order and the log format expects log files to be time-ordered.
- log_level:
The log message level.
- log_part:
The partition the message is in. This column can be changed by an
UPDATEor the :parition-name command.- log_actual_time:
The log messages original timestamp in the file.
- log_idle_msecs:
The difference in time between this messages and the previous. The unit of time is milliseconds.
- log_mark:
True if the log message was marked by the user. This column can be changed by an
UPDATE.- log_comment:
The comment for the message. This column can be changed by an
UPDATEor the :comment command.- log_tags:
A JSON list of tags for the message. This column can be changed by an
UPDATEor the :tag command.- log_annotations:
A JSON object of annotations for this message. This column is populated by the :annotate command.
- log_filters:
A JSON list of filter IDs that matched this message
The following columns are builtin and are hidden, so they will not be
included in a SELECT *:
- log_opid:
The OP ID as captured from the log message or as set by an
UPDATE. Setting the OP ID allows operations to be visualized in the timeline view.- log_user_opid:
The OP ID as set by the user.
- log_format:
The name of the format that parsed this log message.
- log_format_regex:
The name of the format’s regex that matched this message.
- log_time_msecs:
The adjusted timestamp for the log message as the number of milliseconds from the epoch. This column can be more efficient to use for time-related operations, like timeslice().
- log_path:
The path to the log file this message is from.
- log_text:
The full text of the log message.
- log_body:
The body of the log message.
- log_raw_text:
The raw text of this message from the log file. In this case of JSON and CSV logs, this will be the exact line of JSON-Line and CSV text from the file.
- log_line_hash:
A hash of the first line of the log message.
- log_line_link:
The permalink for the log message.
Extensions¶
To make it easier to analyze log data from within lnav, there are several built-in extensions that provide extra functions and collators beyond those provided by SQLite. The majority of the functions are from the extensions-functions.c file available from the sqlite.org web site.
Tip
You can include a SQLite database file on the command-line and use lnav’s interface to perform queries. The database will be attached with a name based on the database file name.
Commands¶
A SQL command is an internal macro implemented by lnav.
.schema- Open the schema view. This view contains a dump of the schema for the internal tables and any tables in attached databases..read- Execute the SQL statements in the given file..dump- Write a file containing SQL statements that can be used to recreate a table..save- Write the contents of the main DB to a SQLite database file. This command is useful if you have created some tables during your analysis and would like to preserve them. The command is implemented using the SQLite Backup API, so it can be run in the background..msgformats- Executes a canned query that groups and counts log messages by the format of their message bodies. This command can be useful for quickly finding out the types of messages that are most common in a log file.
Variables¶
The following variables are available in SQL statements:
$LINES- The number of lines in the terminal window.$COLS- The number of columns in the terminal window.
Environment¶
Environment variables can be accessed in queries using the usual syntax of
$VAR_NAME. For example, to read the value of the “USER” variable, you
can write:
;SELECT $USER
Collators¶
naturalcase - Compare strings “naturally” so that number values in the string are compared based on their numeric value and not their character values. For example, “foo10” would be considered greater than “foo2”.
naturalnocase - The same as naturalcase, but case-insensitive.
ipaddress - Compare IPv4/IPv6 addresses.
loglevel - Compare log levels.
measure_with_units - Compare numbers with unit suffixes. The currently supported suffixes are:
Sizes with an E/P/T/G/M/K prefix.
Seconds with an f/p/n/u/m prefix.
Durations of the form
HH:MM:SSorHH:MM:SS
Reference¶
The following is a reference of the SQL syntax and functions that are available:
SELECT [filter] result-column FROM table WHERE [cond] GROUP BY grouping-expr ORDER BY ordering-term LIMIT limit-expr¶
Query the database and return zero or more rows of data.
- Parameters
filter — Additional processing of rows
result-column — The expression used to generate a result for this column.
table — The table(s) to query for data
cond — The conditions used to select the rows to return.
grouping-expr — The expression to use when grouping rows.
ordering-term — The values to use when ordering the result set.
limit-expr — The maximum number of rows to return.
- Examples
To select all of the columns from the table ‘lnav_example_log’:
;SELECT * FROM lnav_example_log log_line log_part log_time log_actual_time log_idle_msecs log_level log_mark log_comment log_tags log_filters ex_procname ex_duration log_time_msecs log_path log_text log_body 0 <NULL> 2017-02⋯:06.100 2017-02⋯:06.100 0 info 0 <NULL> <NULL> <NULL> hw 2 1486094706000 /tmp/log 2017-02⋯ World! Hello, World! 1 <NULL> 2017-02⋯:06.200 2017-02⋯:06.200 100 error 0 <NULL> <NULL> <NULL> gw 4 1486094706000 /tmp/log 2017-02⋯ World! Goodbye, World! 2 new 2017-02⋯:06.200 2017-02⋯:06.200 1200000 warn 0 <NULL> <NULL> <NULL> gw 1 1486095906000 /tmp/log 2017-02⋯ World! Goodbye, World! 3 new 2017-02⋯:06.200 2017-02⋯:06.200 1800000 debug 0 <NULL> <NULL> <NULL> gw 10 1486097706000 /tmp/log 2017-02⋯ World! Goodbye, World!
expr [NOT] BETWEEN low AND hi¶
Test if an expression is between two values.
- Parameters
low* — The low point
hi* — The high point
- Examples
To check if 3 is between 5 and 10:
;SELECT 3 BETWEEN 5 AND 10 0To check if 10 is between 5 and 10:
;SELECT 10 BETWEEN 5 AND 10 1
ATTACH DATABASE filename AS schema-name¶
Attach a database file to the current connection.
- Parameters
filename* — The path to the database file.
schema-name* — The prefix for tables in this database.
- Examples
To attach the database file ‘/tmp/customers.db’ with the name customers:
;ATTACH DATABASE '/tmp/customers.db' AS customers
CREATE [TEMP] VIEW [IF NOT EXISTS] [schema-name.] view-name AS select-stmt¶
Assign a name to a SELECT statement
- Parameters
IF NOT EXISTS — Do not create the view if it already exists
schema-name. — The database to create the view in
view-name* — The name of the view
select-stmt* — The SELECT statement the view represents
CREATE [TEMP] TABLE [IF NOT EXISTS] [schema-name.] table-name AS select-stmt¶
Create a table
WITH RECURSIVE cte-table-name AS select-stmt¶
Create a temporary view that exists only for the duration of a SQL statement.
- Parameters
cte-table-name* — The name for the temporary table.
select-stmt* — The SELECT statement used to populate the temporary table.
CAST(expr AS type-name)¶
Convert the value of the given expression to a different storage class specified by type-name.
- Parameters
expr* — The value to convert.
type-name* — The name of the type to convert to.
- Examples
To cast the value 1.23 as an integer:
;SELECT CAST(1.23 AS INTEGER) 1
ordering-term COLLATE [collation-name] [direction] [null-handling]¶
The values to use in ordering result rows
- Parameters
direction — The direction, ASCending or DESCending
CASE [base-expr] WHEN cmp-expr ELSE [else-expr] END¶
Evaluate a series of expressions in order until one evaluates to true and then return it’s result. Similar to an IF-THEN-ELSE construct in other languages.
- Parameters
base-expr — The base expression that is used for comparison in the branches
cmp-expr — The expression to test if this branch should be taken
then-expr* — The result for this branch.
else-expr — The result of this CASE if no branches matched.
- Examples
To evaluate the number one and return the string ‘one’:
;SELECT CASE 1 WHEN 0 THEN 'zero' WHEN 1 THEN 'one' END one
expr COLLATE collation-name¶
Assign a collating sequence to the expression.
- Parameters
collation-name* — The name of the collator.
- Examples
To change the collation method for string comparisons:
;SELECT ('a2' < 'a10'), ('a2' < 'a10' COLLATE naturalnocase) ('a2' < 'a10') ('a2' <⋯nocase) 0 1
DETACH DATABASE schema-name¶
Detach a database from the current connection.
- Parameters
schema-name* — The prefix for tables in this database.
- Examples
To detach the database named ‘customers’:
;DETACH DATABASE customers
DELETE FROM table-name WHERE [cond]¶
Delete rows from a table
- Parameters
table-name* — The name of the table
cond — The conditions used to delete the rows.
expr IS expr¶
Test the distinctness of an expression
- Examples
To check if 10 is between 5 and 10:
;SELECT 10 BETWEEN 5 AND 10 1
DROP INDEX [IF EXISTS] [schema-name.] index-name¶
Drop an index
DROP TABLE [IF EXISTS] [schema-name.] table-name¶
Drop a table
DROP VIEW [IF EXISTS] [schema-name.] view-name¶
Drop a view
DROP TRIGGER [IF EXISTS] [schema-name.] trigger-name¶
Drop a trigger
expr [NOT] LIKE pattern ESCAPE [escape]¶
Match an expression against a text pattern.
- Parameters
pattern* — The pattern to match against.
escape — Character used to escape a % or _ in the pattern
- Examples
To check if a value matches the pattern ‘Hello, %!’:
;SELECT 'Hello, World!' LIKE 'Hello, %!' 1
select-stmt¶
Execute a query and return 0 if no rows match or 1 otherwise
FILTER WHERE expr¶
Condition for rows to include in the aggregate
expr [NOT] GLOB pattern¶
Match an expression against a glob pattern.
- Parameters
pattern* — The glob pattern to match against.
- Examples
To check if a value matches the pattern ‘*.log’:
;SELECT 'foobar.log' GLOB '*.log' 1
INSERT INTO [schema-name.] table-name column-name VALUES expr¶
Insert rows into a table
- Examples
To insert the pair containing ‘MSG’ and ‘HELLO, WORLD!’ into the ‘environ’ table:
;INSERT INTO environ VALUES ('MSG', 'HELLO, WORLD!')
expr [nullness]¶
Check an expression against NULL
- Examples
To check if a value is not NULL:
;SELECT 'abc' NOT NULL 1
expr [NOT] REGEXP pattern¶
Match an expression against a regular expression.
- Parameters
pattern* — The regular expression to match against.
- Examples
To check if a value matches the pattern ‘file-d+’:
;SELECT 'file-23' REGEXP 'file-\d+' 1
select-stmt¶
Execute a query and return 1 if no rows match or 0 otherwise
OVER([base-window-name] PARTITION BY expr ORDER BY expr, [frame-spec])¶
Executes the preceding function over a window
- Parameters
base-window-name — The name of the window definition
expr — The values to use for partitioning
expr — The values used to order the rows in the window
frame-spec — Determines which output rows are read by an aggregate window function
OVER window-name¶
Executes the preceding function over a window
- Parameters
window-name* — The name of the window definition
UPDATE table SET column-name WHERE [cond]¶
Modify a subset of values in zero or more rows of the given table
- Parameters
table* — The table to update
column-name — The columns in the table to update.
expr* — The values to place into the column.
cond — The condition used to determine whether a row should be updated.
- Examples
To mark the syslog message at line 40:
;UPDATE syslog_log SET log_mark = 1 WHERE log_line = 40
abs(x)¶
Return the absolute value of the argument
- Parameters
x* — The number to convert
- Examples
To get the absolute value of -1:
;SELECT abs(-1) 1- See Also
acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
acos(num)¶
Returns the arccosine of a number, in radians
- Parameters
num* — A cosine value that is between -1 and 1
- Examples
To get the arccosine of 0.2:
;SELECT printf('%.3f', acos(0.2)) 1.369- See Also
abs(x), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
acosh(num)¶
Returns the hyperbolic arccosine of a number
- Parameters
num* — A number that is one or more
- Examples
To get the hyperbolic arccosine of 1.2:
;SELECT acosh(1.2) 0.6223625037147786- See Also
abs(x), acos(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
anonymize(value)¶
Replace identifying information with random values.
PRQL Name: text.anonymize
- Parameters
value* — The text to anonymize
- Examples
To anonymize an IP address:
;SELECT anonymize('Hello, 192.168.1.2') Aback, 10.0.0.1- See Also
char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
asin(num)¶
Returns the arcsine of a number, in radians
- Parameters
num* — A sine value that is between -1 and 1
- Examples
To get the arcsine of 0.2:
;SELECT asin(0.2) 0.2013579207903308- See Also
abs(x), acos(num), acosh(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
asinh(num)¶
Returns the hyperbolic arcsine of a number
- Parameters
num* — The number
- Examples
To get the hyperbolic arcsine of 0.2:
;SELECT asinh(0.2) 0.19869011034924142- See Also
abs(x), acos(num), acosh(num), asin(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
atan(num)¶
Returns the arctangent of a number, in radians
- Parameters
num* — The number
- Examples
To get the arctangent of 0.2:
;SELECT atan(0.2) 0.19739555984988078- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
atan2(y, x)¶
Returns the angle in the plane between the positive X axis and the ray from (0, 0) to the point (x, y)
- Parameters
y* — The y coordinate of the point
x* — The x coordinate of the point
- Examples
To get the angle, in degrees, for the point at (5, 5):
;SELECT degrees(atan2(5, 5)) 45- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
atanh(num)¶
Returns the hyperbolic arctangent of a number
- Parameters
num* — The number
- Examples
To get the hyperbolic arctangent of 0.2:
;SELECT atanh(0.2) 0.2027325540540822- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
atn2(y, x)¶
Returns the angle in the plane between the positive X axis and the ray from (0, 0) to the point (x, y)
- Parameters
y* — The y coordinate of the point
x* — The x coordinate of the point
- Examples
To get the angle, in degrees, for the point at (5, 5):
;SELECT degrees(atn2(5, 5)) 45- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
avg(X)¶
Returns the average value of all non-NULL numbers within a group.
- Parameters
X* — The value to compute the average of.
- Examples
To get the average of the column ‘ex_duration’ from the table ‘lnav_example_log’:
;SELECT avg(ex_duration) FROM lnav_example_log 4.25To get the average of the column ‘ex_duration’ from the table ‘lnav_example_log’ when grouped by ‘ex_procname’:
;SELECT ex_procname, avg(ex_duration) FROM lnav_example_log GROUP BY ex_procname ex_procname avg(ex_⋯ration) gw 5 hw 2- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
basename(path)¶
Extract the base portion of a pathname.
PRQL Name: fs.basename
- Parameters
path* — The path
- Examples
To get the base of a plain file name:
;SELECT basename('foobar') foobarTo get the base of a path:
;SELECT basename('foo/bar') barTo get the base of a directory:
;SELECT basename('foo/bar/') barTo get the base of an empty string:
;SELECT basename('') .To get the base of a Windows path:
;SELECT basename('foo\bar') barTo get the base of the root directory:
;SELECT basename('/') /To get the base of a path:
;from [{p='foo/bar'}] | select { fs.basename p } bar- See Also
dirname(path), joinpath(path), readlink(path), realpath(path)
ceil(num)¶
Returns the smallest integer that is not less than the argument
- Parameters
num* — The number to raise to the ceiling
- Examples
To get the ceiling of 1.23:
;SELECT ceil(1.23) 2- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
changes()¶
The number of database rows that were changed, inserted, or deleted by the most recent statement.
char(X)¶
Returns a string composed of characters having the given unicode code point values
- Parameters
X — The unicode code point values
- Examples
To get a string with the code points 0x48 and 0x49:
;SELECT char(0x48, 0x49) HI- See Also
anonymize(value), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
charindex(needle, haystack, [start])¶
Finds the first occurrence of the needle within the haystack and returns the number of prior characters plus 1, or 0 if Y is nowhere found within X
- Parameters
needle* — The string to look for in the haystack
haystack* — The string to search within
start — The one-based index within the haystack to start the search
- Examples
To search for the string ‘abc’ within ‘abcabc’ and starting at position 2:
;SELECT charindex('abc', 'abcabc', 2) 4To search for the string ‘abc’ within ‘abcdef’ and starting at position 2:
;SELECT charindex('abc', 'abcdef', 2) 0- See Also
anonymize(value), char(X), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
coalesce(X, Y)¶
Returns a copy of its first non-NULL argument, or NULL if all arguments are NULL
- Parameters
X* — A value to check for NULL-ness
Y — A value to check for NULL-ness
- Examples
To get the first non-null value from three parameters:
;SELECT coalesce(null, 0, null) 0
concat(X)¶
Returns a string that is the concatenation of all non-NULL arguments
- Parameters
X — The values to concatenate together
- Examples
To concatenate a label and number:
;SELECT concat('Size: ', 1234) Size: 1234- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
concat_ws(sep, X)¶
Returns a string that is the concatenation of all non-NULL arguments separated by the first argument
- Parameters
sep* — The separator
X — The values to concatenate together
- Examples
To separate numbers with a comma:
;SELECT concat_ws(',', 1, 2, 3, 4) 1,2,3,4- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
count(X)¶
If the argument is ‘*’, the total number of rows in the group is returned. Otherwise, the number of times the argument is non-NULL.
- Parameters
X* — The value to count.
- Examples
To get the count of the non-NULL rows of ‘lnav_example_log’:
;SELECT count(*) FROM lnav_example_log 4To get the count of the non-NULL values of ‘log_part’ from ‘lnav_example_log’:
;SELECT count(log_part) FROM lnav_example_log 2
cume_dist()¶
Returns the cumulative distribution
date(timestring, modifier)¶
Returns the date in this format: YYYY-MM-DD.
- Parameters
timestring* — The string to convert to a date.
modifier — A transformation that is applied to the value to the left.
- Examples
To get the date portion of the timestamp ‘2017-01-02T03:04:05’:
;SELECT date('2017-01-02T03:04:05') 2017-01-02To get the date portion of the timestamp ‘2017-01-02T03:04:05’ plus one day:
;SELECT date('2017-01-02T03:04:05', '+1 day') 2017-01-03To get the date portion of the epoch timestamp 1491341842:
;SELECT date(1491341842, 'unixepoch') 2017-04-04- See Also
datetime(timestring, modifier), humanize_duration(secs), julianday(timestring, modifier), strftime(format, timestring, modifier), time(timestring, modifier), timediff(time1, time2), timeslice(time, slice), timezone(tz, ts)
datetime(timestring, modifier)¶
Returns the date and time in this format: YYYY-MM-DD HH:MM:SS.
- Parameters
timestring* — The string to convert to a date with time.
modifier — A transformation that is applied to the value to the left.
- Examples
To get the date and time portion of the timestamp ‘2017-01-02T03:04:05’:
;SELECT datetime('2017-01-02T03:04:05') 2017-01-02 03:04:05To get the date and time portion of the timestamp ‘2017-01-02T03:04:05’ plus one minute:
;SELECT datetime('2017-01-02T03:04:05', '+1 minute') 2017-01-02 03:05:05To get the date and time portion of the epoch timestamp 1491341842:
;SELECT datetime(1491341842, 'unixepoch') 2017-04-04 21:37:22- See Also
date(timestring, modifier), humanize_duration(secs), julianday(timestring, modifier), strftime(format, timestring, modifier), time(timestring, modifier), timediff(time1, time2), timeslice(time, slice), timezone(tz, ts)
decode(value, algorithm)¶
Decode the value using the given algorithm
- Parameters
value* — The value to decode
algorithm* — One of the following encoding algorithms: base64, hex, uri
- Examples
To decode the URI-encoded string ‘%63%75%72%6c’:
;SELECT decode('%63%75%72%6c', 'uri') curl- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
degrees(radians)¶
Converts radians to degrees
- Parameters
radians* — The radians value to convert to degrees
- Examples
To convert PI to degrees:
;SELECT degrees(pi()) 180- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
dense_rank()¶
Returns the row_number() of the first peer in each group without gaps
dirname(path)¶
Extract the directory portion of a pathname.
PRQL Name: fs.dirname
- Parameters
path* — The path
- Examples
To get the directory of a relative file path:
;SELECT dirname('foo/bar') fooTo get the directory of an absolute file path:
;SELECT dirname('/foo/bar') /fooTo get the directory of a file in the root directory:
;SELECT dirname('/bar') /To get the directory of a Windows path:
;SELECT dirname('foo\bar') fooTo get the directory of an empty path:
;SELECT dirname('') .- See Also
basename(path), joinpath(path), readlink(path), realpath(path)
echoln(value)¶
Echo the argument to the current output file and return it
- Parameters
value* — The value to write to the current output file
- See Also
:append-to path, ;.dump path table, ;.read path, ;.save path, :echo [-n] msg, :export-session-to path, :open [–since] [–until] path, :pipe-line-to shell-cmd, :pipe-to shell-cmd, :redirect-to [path], :write-csv-to [–anonymize] path, :write-json-cols-to [–anonymize] path, :write-json-to [–anonymize] path, :write-jsonlines-to [–all] [–anonymize] path, :write-raw-to [–view] [–anonymize] path, :write-screen-to [–anonymize] path, :write-table-to [–anonymize] path, :write-to [–anonymize] path, :write-view-to [–anonymize] path, :xopen path
encode(value, algorithm)¶
Encode the value using the given algorithm
- Parameters
value* — The value to encode
algorithm* — One of the following encoding algorithms: base64, hex, uri, html
- Examples
To base64-encode ‘Hello, World!’:
;SELECT encode('Hello, World!', 'base64') SGVsbG8sIFdvcmxkIQ==To hex-encode ‘Hello, World!’:
;SELECT encode('Hello, World!', 'hex') 48656c6c6f2c20576f726c6421To URI-encode ‘Hello, World!’:
;SELECT encode('Hello, World!', 'uri') Hello%2C%20World%21- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
endswith(str, suffix)¶
Test if a string ends with the given suffix
- Parameters
str* — The string to test
suffix* — The suffix to check in the string
- Examples
To test if the string ‘notbad.jpg’ ends with ‘.jpg’:
;SELECT endswith('notbad.jpg', '.jpg') 1To test if the string ‘notbad.png’ starts with ‘.jpg’:
;SELECT endswith('notbad.png', '.jpg') 0- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
exp(x)¶
Returns the value of e raised to the power of x
- Parameters
x* — The exponent
- Examples
To raise e to 2:
;SELECT exp(2) 7.38905609893065- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
extract(str)¶
Automatically Parse and extract data from a string
PRQL Name: text.discover
- Parameters
str* — The string to parse
- Examples
To extract key/value pairs from a string:
;SELECT extract('foo=1 bar=2 name="Rolo Tomassi"') {"foo":1,"bar":2,"name":"Rolo Tomassi"}To extract columnar data from a string:
;SELECT extract('1.0 abc 2.0') {"col_0":1.0,"col_1":2.0}- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
first_value(expr)¶
Returns the result of evaluating the expression against the first row in the window frame.
- Parameters
expr* — The expression to execute over the first row
- See Also
cume_dist(), dense_rank(), lag(expr, [offset], [default]), last_value(expr), lead(expr, [offset], [default]), nth_value(expr, N), ntile(groups), percent_rank(), rank(), row_number()
floor(num)¶
Returns the largest integer that is not greater than the argument
- Parameters
num* — The number to lower to the floor
- Examples
To get the floor of 1.23:
;SELECT floor(1.23) 1- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
fstat(pattern)¶
A table-valued function for getting information about file paths/globs
- Parameters
pattern* — The file path or glob pattern to query.
- Examples
To read a file and raise an error if there is a problem:
;SELECT ifnull(data, raise_error('cannot read: ' || st_name, error)) FROM fstat('/non-existent') error: cannot read: non-existent reason: No such file or directory --> fstat:1 | SELECT ifnull(data, raise_error('cannot read: ' || st_name, error)) FROM fstat('/non-existent')
fuzzy_match(pattern, str)¶
Perform a fuzzy match of a pattern against a string and return a score or NULL if the pattern was not matched
- Parameters
pattern* — The pattern to look for in the string
str* — The string to match against
- Examples
To match the pattern ‘fo’ against ‘filter-out’:
;SELECT fuzzy_match('fo', 'filter-out') 137- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
generate_series(start, stop, [step])¶
A table-valued-function that returns the whole numbers between a lower and upper bound, inclusive
- Parameters
start* — The starting point of the series
stop* — The stopping point of the series
step — The increment between each value
- Examples
To generate the numbers in the range [10, 14]:
;SELECT value FROM generate_series(10, 14) value 10 11 12 13 14To generate every other number in the range [10, 14]:
;SELECT value FROM generate_series(10, 14, 2) value 10 12 14To count down from five to 1:
;SELECT value FROM generate_series(1, 5, -1) value 5 4 3 2 1
gethostbyaddr(hostname)¶
Get the hostname for the given IP address
PRQL Name: net.gethostbyaddr
- Parameters
hostname* — The IP address to lookup.
- Examples
To get the hostname for the IP ‘127.0.0.1’:
;SELECT gethostbyaddr('127.0.0.1') localhost- See Also
gethostbyname(hostname)¶
Get the IP address for the given hostname
PRQL Name: net.gethostbyname
- Parameters
hostname* — The DNS hostname to lookup.
- Examples
To get the IP address for ‘localhost’:
;SELECT gethostbyname('localhost') 127.0.0.1- See Also
glob(pattern, str)¶
Match a string against Unix glob pattern
- Parameters
pattern* — The glob pattern
str* — The string to match
- Examples
To test if the string ‘abc’ matches the glob ‘a*’:
;SELECT glob('a*', 'abc') 1
group_concat(X, [sep])¶
Returns a string which is the concatenation of all non-NULL values of X separated by a comma or the given separator.
- Parameters
X* — The value to concatenate.
sep — The separator to place between the values.
- Examples
To concatenate the values of the column ‘ex_procname’ from the table ‘lnav_example_log’:
;SELECT group_concat(ex_procname) FROM lnav_example_log hw,gw,gw,gwTo join the values of the column ‘ex_procname’ using the string ‘, ‘:
;SELECT group_concat(ex_procname, ', ') FROM lnav_example_log hw, gw, gw, gwTo concatenate the distinct values of the column ‘ex_procname’ from the table ‘lnav_example_log’:
;SELECT group_concat(DISTINCT ex_procname) FROM lnav_example_log hw,gw- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
group_spooky_hash(str)¶
Compute the hash value for the given arguments
- Parameters
str — The string to hash
- Examples
To produce a hash of all of the values of ‘column1’:
;SELECT group_spooky_hash(column1) FROM (VALUES ('abc'), ('123')) 4e7a190aead058cb123c94290f29c34a- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
gunzip(b)¶
Decompress a gzip file
- Parameters
b — The blob to decompress
- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
gzip(value)¶
Compress a string into a gzip file
- Parameters
value — The value to compress
- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
hex(X)¶
Returns a string which is the upper-case hexadecimal rendering of the content of its argument.
- Parameters
X* — The blob to convert to hexadecimal
- Examples
To get the hexadecimal rendering of the string ‘abc’:
;SELECT hex('abc') 616263
humanize_duration(secs)¶
Format the given seconds value as an abbreviated duration string
PRQL Name: humanize.duration
- Parameters
secs* — The duration in seconds
- Examples
To format a duration:
;SELECT humanize_duration(15 * 60) 15m00sTo format a sub-second value:
;SELECT humanize_duration(1.5) 1s500ms- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), date(timestring, modifier), datetime(timestring, modifier), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_file_size(value), humanize_id(id), instr(haystack, needle), julianday(timestring, modifier), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), strftime(format, timestring, modifier), substr(str, start, [size]), time(timestring, modifier), timediff(time1, time2), timeslice(time, slice), timezone(tz, ts), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
humanize_file_size(value)¶
Format the given file size as a human-friendly string
PRQL Name: humanize.file_size
- Parameters
value* — The file size to format
- Examples
To format an amount:
;SELECT humanize_file_size(10 * 1024 * 1024) 10.0MB- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
humanize_id(id)¶
Colorize the given ID using ANSI escape codes.
PRQL Name: humanize.id
- Parameters
id* — The identifier to color
- Examples
To colorize the ID ‘cluster1’:
;SELECT humanize_id('cluster1') cluster1- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
ifnull(X, Y)¶
Returns a copy of its first non-NULL argument, or NULL if both arguments are NULL
- Parameters
X* — A value to check for NULL-ness
Y* — A value to check for NULL-ness
- Examples
To get the first non-null value between null and zero:
;SELECT ifnull(null, 0) 0
instr(haystack, needle)¶
Finds the first occurrence of the needle within the haystack and returns the number of prior characters plus 1, or 0 if the needle was not found
- Parameters
haystack* — The string to search within
needle* — The string to look for in the haystack
- Examples
To test get the position of ‘b’ in the string ‘abc’:
;SELECT instr('abc', 'b') 2- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
jget(json, ptr, [default])¶
Get the value from a JSON object using a JSON-Pointer.
PRQL Name: json.get
- Parameters
json* — The JSON object to query.
ptr* — The JSON-Pointer to lookup in the object.
default — The default value if the value was not found
- Examples
To get the root of a JSON value:
;SELECT jget('1', '') 1To get the property named ‘b’ in a JSON object:
;SELECT jget('{ "a": 1, "b": 2 }', '/b') 2To get the ‘msg’ property and return a default if it does not exist:
;SELECT jget(null, '/msg', 'Hello') Hello- See Also
json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
joinpath(path)¶
Join components of a path together.
PRQL Name: fs.join
- Parameters
path — One or more path components to join together. If an argument starts with a forward or backward slash, it will be considered an absolute path and any preceding elements will be ignored.
- Examples
To join a directory and file name into a relative path:
;SELECT joinpath('foo', 'bar') foo/barTo join an empty component with other names into a relative path:
;SELECT joinpath('', 'foo', 'bar') foo/barTo create an absolute path with two path components:
;SELECT joinpath('/', 'foo', 'bar') /foo/barTo create an absolute path from a path component that starts with a forward slash:
;SELECT joinpath('/', 'foo', '/bar') /bar- See Also
basename(path), dirname(path), readlink(path), realpath(path)
json(X)¶
Verifies that its argument is valid JSON and returns a minified version or throws an error.
- Parameters
X* — The string to interpret as JSON.
- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), yaml_to_json(yaml)
json_array(X)¶
Constructs a JSON array from its arguments.
- Parameters
X — The values of the JSON array
- Examples
To create an array of all types:
;SELECT json_array(NULL, 1, 2.1, 'three', json_array(4), json_object('five', 'six')) [null,1,2.1,"three",[4],{"five":"six"}]To create an empty array:
;SELECT json_array() []- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_array_length(X, [P])¶
Returns the length of a JSON array.
- Parameters
X* — The JSON object.
P — The path to the array in ‘X’.
- Examples
To get the length of an array:
;SELECT json_array_length('[1, 2, 3]') 3To get the length of a nested array:
;SELECT json_array_length('{"arr": [1, 2, 3]}', '$.arr') 3- See Also
jget(json, ptr, [default]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_concat(json, value)¶
Returns an array with the given values concatenated onto the end. If the initial value is null, the result will be an array with the given elements. If the initial value is an array, the result will be an array with the given values at the end. If the initial value is not null or an array, the result will be an array with two elements: the initial value and the given value.
PRQL Name: json.concat
- Parameters
json* — The initial JSON value.
value — The value(s) to add to the end of the array.
- Examples
To append the number 4 to null:
;SELECT json_concat(NULL, 4) [4]To append 4 and 5 to the array [1, 2, 3]:
;SELECT json_concat('[1, 2, 3]', 4, 5) [1,2,3,4,5]To concatenate two arrays together:
;SELECT json_concat('[1, 2, 3]', json('[4, 5]')) [1,2,3,4,5]- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_contains(json, value)¶
Check if a JSON value contains the given element.
PRQL Name: json.contains
- Parameters
json* — The JSON value to query.
value* — The value to look for in the first argument
- Examples
To test if a JSON array contains the number 4:
;SELECT json_contains('[1, 2, 3]', 4) 0To test if a JSON array contains the string ‘def’:
;SELECT json_contains('["abc", "def"]', 'def') 1- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_each(X, [P])¶
A table-valued-function that returns the children of the top-level JSON value
- Parameters
X* — The JSON value to query
P — The path to the value to query
- Examples
To iterate over an array:
;SELECT * FROM json_each('[null,1,"two",{"three":4.5}]') key value type atom id parent fullkey path 0 <NULL> null <NULL> 2 <NULL> $[0] $ 1 1 integer 1 3 <NULL> $[1] $ 2 two text two 5 <NULL> $[2] $ 3 {"three":4.5} object <NULL> 9 <NULL> $[3] $- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_extract(X, P)¶
Returns the value(s) from the given JSON at the given path(s).
- Parameters
X* — The JSON value.
P — The path to extract.
- Examples
To get a number:
;SELECT json_extract('{"num": 1}', '$.num') 1To get two numbers:
;SELECT json_extract('{"num": 1, "val": 2}', '$.num', '$.val') [1,2]To get an object:
;SELECT json_extract('{"obj": {"sub": 1}}', '$.obj') {"sub":1}- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_group_array(value)¶
Collect the given values from a query into a JSON array
PRQL Name: json.group_array
- Parameters
value — The values to append to the array
- Examples
To create an array from arguments:
;SELECT json_group_array('one', 2, 3.4) ["one",2,3.3999999999999999112]To create an array from a column of values:
;SELECT json_group_array(column1) FROM (VALUES (1), (2), (3)) [1,2,3]- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_group_object(name, value)¶
Collect the given values from a query into a JSON object
PRQL Name: json.group_object
- Parameters
name* — The property name for the value
value — The value to add to the object
- Examples
To create an object from arguments:
;SELECT json_group_object('a', 1, 'b', 2) {"a":1,"b":2}To create an object from a pair of columns:
;SELECT json_group_object(column1, column2) FROM (VALUES ('a', 1), ('b', 2)) {"a":1,"b":2}- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_insert(X, P, Y)¶
Inserts values into a JSON object/array at the given locations, if it does not already exist
- Parameters
X* — The JSON value to update
P* — The path to the insertion point. A ‘#’ array index means append the value
Y* — The value to insert
- Examples
To append to an array:
;SELECT json_insert('[1, 2]', '$[#]', 3) [1,2,3]To update an object:
;SELECT json_insert('{"a": 1}', '$.b', 2) {"a":1,"b":2}To ensure a value is set:
;SELECT json_insert('{"a": 1}', '$.a', 2) {"a":1}To update multiple values:
;SELECT json_insert('{"a": 1}', '$.b', 2, '$.c', 3) {"a":1,"b":2,"c":3}- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_object(N, V)¶
Create a JSON object from the given arguments
- Parameters
N* — The property name
V* — The property value
- Examples
To create an object:
;SELECT json_object('a', 1, 'b', 'c') {"a":1,"b":"c"}To create an empty object:
;SELECT json_object() {}- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_object_count_of(value)¶
Count the number of times the argument has been seen
PRQL Name: json.object_count_of
- Parameters
value* — The value to count in the object
- Examples
To count the number of message for each level:
;SELECT json_object_count_of(log_level) FROM lnav_example_log {"info":1,"error":1,"debug":1,"warn":1}
json_object_sum_of(id, value)¶
Sum values for an associated identifier
PRQL Name: json.object_sum_of
- Parameters
id* — The identifier to track
value* — The value to sum
json_quote(X)¶
Returns the JSON representation of the given value, if it is not already JSON
- Parameters
X* — The value to convert
- Examples
To convert a string:
;SELECT json_quote('Hello, World!') "Hello, World!"To pass through an existing JSON value:
;SELECT json_quote(json('"Hello, World!"')) "Hello, World!"- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_remove(X, P)¶
Removes paths from a JSON value
- Parameters
X* — The JSON value to update
P — The paths to remove
- Examples
To remove elements of an array:
;SELECT json_remove('[1,2,3]', '$[1]', '$[1]') [1]To remove object properties:
;SELECT json_remove('{"a":1,"b":2}', '$.b') {"a":1}- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_replace(X, P, Y)¶
Replaces existing values in a JSON object/array at the given locations
- Parameters
X* — The JSON value to update
P* — The path to replace
Y* — The new value for the property
- Examples
To replace an existing value:
;SELECT json_replace('{"a": 1}', '$.a', 2) {"a":2}To replace a value without creating a new property:
;SELECT json_replace('{"a": 1}', '$.a', 2, '$.b', 3) {"a":2}- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_set(X, P, Y)¶
Inserts or replaces existing values in a JSON object/array at the given locations
- Parameters
X* — The JSON value to update
P* — The path to the insertion point. A ‘#’ array index means append the value
Y* — The value to set
- Examples
To replace an existing array element:
;SELECT json_set('[1, 2]', '$[1]', 3) [1,3]To replace a value and create a new property:
;SELECT json_set('{"a": 1}', '$.a', 2, '$.b', 3) {"a":2,"b":3}- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_tree(X, [P])¶
A table-valued-function that recursively descends through a JSON value
- Parameters
X* — The JSON value to query
P — The path to the value to query
- Examples
To iterate over an array:
;SELECT key,value,type,atom,fullkey,path FROM json_tree('[null,1,"two",{"three":4.5}]') key value type atom fullkey path <NULL> [null,1⋯":4.5}] array <NULL> $ $ 0 <NULL> null <NULL> $[0] $ 1 1 integer 1 $[1] $ 2 two text two $[2] $ 3 {"three":4.5} object <NULL> $[3] $ three 4.5 real 4.5 $[3].three $[3]- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_type(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_type(X, [P])¶
Returns the type of a JSON value
- Parameters
X* — The JSON value to query
P — The path to the value
- Examples
To get the type of a value:
;SELECT json_type('[null,1,2.1,"three",{"four":5}]') arrayTo get the type of an array element:
;SELECT json_type('[null,1,2.1,"three",{"four":5}]', '$[0]') nullTo get the type of a string:
;SELECT json_type('[null,1,2.1,"three",{"four":5}]', '$[3]') text- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_valid(X), json(X), yaml_to_json(yaml)
json_valid(X)¶
Tests if the given value is valid JSON
- Parameters
X* — The value to check
- Examples
To check an empty string:
;SELECT json_valid('') 0To check a string:
;SELECT json_valid('"a"') 1- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json(X), yaml_to_json(yaml)
julianday(timestring, modifier)¶
Returns the number of days since noon in Greenwich on November 24, 4714 B.C.
- Parameters
timestring* — The string to convert to a date with time.
modifier — A transformation that is applied to the value to the left.
- Examples
To get the julian day from the timestamp ‘2017-01-02T03:04:05’:
;SELECT julianday('2017-01-02T03:04:05') 2457755.627835648To get the julian day from the timestamp ‘2017-01-02T03:04:05’ plus one minute:
;SELECT julianday('2017-01-02T03:04:05', '+1 minute') 2457755.6285300925To get the julian day from the timestamp 1491341842:
;SELECT julianday(1491341842, 'unixepoch') 2457848.400949074- See Also
date(timestring, modifier), datetime(timestring, modifier), humanize_duration(secs), strftime(format, timestring, modifier), time(timestring, modifier), timediff(time1, time2), timeslice(time, slice), timezone(tz, ts)
lag(expr, [offset], [default])¶
Returns the result of evaluating the expression against the previous row in the partition.
- Parameters
expr* — The expression to execute over the previous row
offset — The offset from the current row in the partition
default — The default value if the previous row does not exist instead of NULL
- See Also
cume_dist(), dense_rank(), first_value(expr), last_value(expr), lead(expr, [offset], [default]), nth_value(expr, N), ntile(groups), percent_rank(), rank(), row_number()
last_insert_rowid()¶
Returns the ROWID of the last row insert from the database connection which invoked the function
last_value(expr)¶
Returns the result of evaluating the expression against the last row in the window frame.
- Parameters
expr* — The expression to execute over the last row
- See Also
cume_dist(), dense_rank(), first_value(expr), lag(expr, [offset], [default]), lead(expr, [offset], [default]), nth_value(expr, N), ntile(groups), percent_rank(), rank(), row_number()
lead(expr, [offset], [default])¶
Returns the result of evaluating the expression against the next row in the partition.
- Parameters
expr* — The expression to execute over the next row
offset — The offset from the current row in the partition
default — The default value if the next row does not exist instead of NULL
- See Also
cume_dist(), dense_rank(), first_value(expr), lag(expr, [offset], [default]), last_value(expr), nth_value(expr, N), ntile(groups), percent_rank(), rank(), row_number()
leftstr(str, N)¶
Returns the N leftmost (UTF-8) characters in the given string.
- Parameters
str* — The string to return subset.
N* — The number of characters from the left side of the string to return.
- Examples
To get the first character of the string ‘abc’:
;SELECT leftstr('abc', 1) aTo get the first ten characters of a string, regardless of size:
;SELECT leftstr('abc', 10) abc- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
length(str)¶
Returns the number of characters (not bytes) in the given string prior to the first NUL character
- Parameters
str* — The string to determine the length of
- Examples
To get the length of the string ‘abc’:
;SELECT length('abc') 3- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
like(pattern, str, [escape])¶
Match a string against a pattern
- Parameters
pattern* — The pattern to match. A percent symbol (%) will match zero or more characters and an underscore (_) will match a single character.
str* — The string to match
escape — The escape character that can be used to prefix a literal percent or underscore in the pattern.
- Examples
To test if the string ‘aabcc’ contains the letter ‘b’:
;SELECT like('%b%', 'aabcc') 1To test if the string ‘aab%’ ends with ‘b%’:
;SELECT like('%b:%', 'aab%', ':') 1
likelihood(value, probability)¶
Provides a hint to the query planner that the first argument is a boolean that is true with the given probability
- Parameters
value* — The boolean value to return
probability* — A floating point constant between 0.0 and 1.0
likely(value)¶
Short-hand for likelihood(X,0.9375)
- Parameters
value* — The boolean value to return
load_extension(path, [entry-point])¶
Loads SQLite extensions out of the given shared library file using the given entry point.
- Parameters
path* — The path to the shared library containing the extension.
log(x)¶
Returns the natural logarithm of x
- Parameters
x* — The number
- Examples
To get the natual logarithm of 8:
;SELECT log(8) 2.0794415416798357- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
log10(x)¶
Returns the base-10 logarithm of X
- Parameters
x* — The number
- Examples
To get the logarithm of 100:
;SELECT log10(100) 2- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
log_msg_line()¶
Return the starting line number of the focused log message.
PRQL Name: lnav.view.msg_line
log_top_datetime()¶
Return the timestamp of the line at the top of the log view.
PRQL Name: lnav.view.top_datetime
log_top_line()¶
Return the number of the focused line of the log view.
PRQL Name: lnav.view.top_line
logfmt2json(str)¶
Convert a logfmt-encoded string into JSON
PRQL Name: logfmt.to_json
- Parameters
str* — The logfmt message to parse
- Examples
To extract key/value pairs from a log message:
;SELECT logfmt2json('foo=1 bar=2 name="Rolo Tomassi"') {"foo":1,"bar":2,"name":"Rolo Tomassi"}- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
lower(str)¶
Returns a copy of the given string with all ASCII characters converted to lower case.
- Parameters
str* — The string to convert.
- Examples
To lowercase the string ‘AbC’:
;SELECT lower('AbC') abc- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
ltrim(str, [chars])¶
Returns a string formed by removing any and all characters that appear in the second argument from the left side of the first.
- Parameters
str* — The string to trim characters from the left side
chars — The characters to trim. Defaults to spaces.
- Examples
To trim the leading space characters from the string ‘ abc’:
;SELECT ltrim(' abc') abcTo trim the characters ‘a’ or ‘b’ from the left side of the string ‘aaaabbbc’:
;SELECT ltrim('aaaabbbc', 'ab') c- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
max(X)¶
Returns the argument with the maximum value, or return NULL if any argument is NULL.
- Parameters
X — The numbers to find the maximum of. If only one argument is given, this function operates as an aggregate.
- Examples
To get the largest value from the parameters:
;SELECT max(2, 1, 3) 3To get the largest value from an aggregate:
;SELECT max(status) FROM http_status_codes 511- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
min(X)¶
Returns the argument with the minimum value, or return NULL if any argument is NULL.
- Parameters
X — The numbers to find the minimum of. If only one argument is given, this function operates as an aggregate.
- Examples
To get the smallest value from the parameters:
;SELECT min(2, 1, 3) 1To get the smallest value from an aggregate:
;SELECT min(status) FROM http_status_codes 100- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
nth_value(expr, N)¶
Returns the result of evaluating the expression against the nth row in the window frame.
- Parameters
expr* — The expression to execute over the nth row
N* — The row number
- See Also
cume_dist(), dense_rank(), first_value(expr), lag(expr, [offset], [default]), last_value(expr), lead(expr, [offset], [default]), ntile(groups), percent_rank(), rank(), row_number()
ntile(groups)¶
Returns the number of the group that the current row is a part of
- Parameters
groups* — The number of groups
- See Also
cume_dist(), dense_rank(), first_value(expr), lag(expr, [offset], [default]), last_value(expr), lead(expr, [offset], [default]), nth_value(expr, N), percent_rank(), rank(), row_number()
nullif(X, Y)¶
Returns its first argument if the arguments are different and NULL if the arguments are the same.
- Parameters
X* — The first argument to compare.
Y* — The argument to compare against the first.
- Examples
To test if 1 is different from 1:
;SELECT nullif(1, 1) <NULL>To test if 1 is different from 2:
;SELECT nullif(1, 2) 1
octet_length(X)¶
Returns the number of bytes in the given string as encoded in the database
- Parameters
X* — The value to examine
- Examples
To get the number of bytes for a string:
;SELECT octet_length('Hello, World!') 13To get the number of bytes for a number:
;SELECT octet_length(42) 2
padc(str, len)¶
Pad the given string with enough spaces to make it centered within the given length
- Parameters
str* — The string to pad
len* — The minimum desired length of the output string
- Examples
To pad the string ‘abc’ to a length of six characters:
;SELECT padc('abc', 6) || 'def' abc defTo pad the string ‘abcdef’ to a length of eight characters:
;SELECT padc('abcdef', 8) || 'ghi' abcdef ghi- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
padl(str, len)¶
Pad the given string with leading spaces until it reaches the desired length
- Parameters
str* — The string to pad
len* — The minimum desired length of the output string
- Examples
To pad the string ‘abc’ to a length of six characters:
;SELECT padl('abc', 6) abcTo pad the string ‘abcdef’ to a length of four characters:
;SELECT padl('abcdef', 4) abcdef- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
padr(str, len)¶
Pad the given string with trailing spaces until it reaches the desired length
- Parameters
str* — The string to pad
len* — The minimum desired length of the output string
- Examples
To pad the string ‘abc’ to a length of six characters:
;SELECT padr('abc', 6) || 'def' abc defTo pad the string ‘abcdef’ to a length of four characters:
;SELECT padr('abcdef', 4) || 'ghi' abcdefghi- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
parse_url(url)¶
Parse a URL and return the components in a JSON object. Limitations: not all URL schemes are supported and repeated query parameters are not captured.
- Parameters
url* — The URL to parse
- Examples
To parse the URL ‘https://example.com/search?q=hello%20world’:
;SELECT parse_url('https://example.com/search?q=hello%20world') {"scheme":"https","username":null,"password":null,"host":"example.com","port":null,"path":"/search","query":"q=hello%20world","parameters":{"q":"hello world"},"fragment":null}To parse the URL ‘https://alice@[fe80::14ff:4ee5:1215:2fb2]’:
;SELECT parse_url('https://alice@[fe80::14ff:4ee5:1215:2fb2]') {"scheme":"https","username":"alice","password":null,"host":"[fe80::14ff:4ee5:1215:2fb2]","port":null,"path":"/","query":null,"parameters":null,"fragment":null}- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
percent_rank()¶
Returns (rank - 1) / (partition-rows - 1)
pi()¶
Returns the value of PI
- Examples
To get the value of PI:
;SELECT pi() 3.141592653589793- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
power(base, exp)¶
Returns the base to the given exponent
- Parameters
base* — The base number
exp* — The exponent
- Examples
To raise two to the power of three:
;SELECT power(2, 3) 8- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X), total(X)
pretty_print(str)¶
Pretty-print the given string
PRQL Name: text.pretty
- Parameters
str* — The string to format
- Examples
To pretty-print the string ‘{“scheme”: “https”, “host”: “example.com”}’:
;SELECT pretty_print('{"scheme": "https", "host": "example.com"}') { "scheme": "https", "host": "example.com" }- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
printf(format, X)¶
Returns a string with this functions arguments substituted into the given format. Substitution points are specified using percent (%) options, much like the standard C printf() function.
- Parameters
format* — The format of the string to return.
X* — The argument to substitute at a given position in the format.
- Examples
To substitute ‘World’ into the string ‘Hello, %s!’:
;SELECT printf('Hello, %s!', 'World') Hello, World!To right-align ‘small’ in the string ‘align:’ with a column width of 10:
;SELECT printf('align: % 10s', 'small') align: smallTo format 11 with a width of five characters and leading zeroes:
;SELECT printf('value: %05d', 11) value: 00011- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
proper(str)¶
Capitalize the first character of words in the given string
- Parameters
str* — The string to capitalize.
- Examples
To capitalize the words in the string ‘hello, world!’:
;SELECT proper('hello, world!') Hello, World!- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
quote(X)¶
Returns the text of an SQL literal which is the value of its argument suitable for inclusion into an SQL statement.
- Parameters
X* — The string to quote.
- Examples
To quote the string ‘abc’:
;SELECT quote('abc') 'abc'To quote the string ‘abc’123’:
;SELECT quote('abc''123') 'abc''123'
radians(degrees)¶
Converts degrees to radians
- Parameters
degrees* — The degrees value to convert to radians
- Examples
To convert 180 degrees to radians:
;SELECT radians(180) 3.141592653589793- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), round(num, [digits]), sign(num), square(num), sum(X), total(X)
raise_error(msg, [reason], [help])¶
Raises an error with the given message when executed
- Parameters
msg* — The error message
reason — The reason the error occurred
help — A possible resolution to the error
- Examples
To raise an error if a variable is not set:
;SELECT ifnull($val, raise_error('please set $val', 'because')) error: please set $val reason: because --> raise_error:1 | SELECT ifnull($val, raise_error('please set $val', 'because'))
random()¶
Returns a pseudo-random integer between -9223372036854775808 and +9223372036854775807.
randomblob(N)¶
Return an N-byte blob containing pseudo-random bytes.
- Parameters
N* — The size of the blob in bytes.
rank()¶
Returns the row_number() of the first peer in each group with gaps
readlink(path)¶
Read the target of a symbolic link.
PRQL Name: fs.readlink
- Parameters
path* — The path to the symbolic link.
- See Also
basename(path), dirname(path), joinpath(path), realpath(path)
realpath(path)¶
Returns the resolved version of the given path, expanding symbolic links and resolving ‘.’ and ‘..’ references.
PRQL Name: fs.realpath
- Parameters
path* — The path to resolve.
- See Also
basename(path), dirname(path), joinpath(path), readlink(path)
regexp(re, str)¶
Test if a string matches a regular expression
- Parameters
re* — The regular expression to use
str* — The string to test against the regular expression
regexp_capture(string, pattern)¶
A table-valued function that executes a regular-expression over a string and returns the captured values. If the regex only matches a subset of the input string, it will be rerun on the remaining parts of the string until no more matches are found.
- Parameters
string* — The string to match against the given pattern.
pattern* — The regular expression to match.
- Examples
To extract the key/value pairs ‘a’/1 and ‘b’/2 from the string ‘a=1; b=2’:
;SELECT * FROM regexp_capture('a=1; b=2', '(\w+)=(\d+)') match_index capture_index capture_name capture_count range_start range_stop content 0 0 <NULL> 3 1 4 a=1 0 1 <NULL> 3 1 2 a 0 2 <NULL> 3 3 4 1 1 0 <NULL> 3 6 9 b=2 1 1 <NULL> 3 6 7 b 1 2 <NULL> 3 8 9 2- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
regexp_capture_into_json(string, pattern, [options])¶
A table-valued function that executes a regular-expression over a string and returns the captured values as a JSON object. If the regex only matches a subset of the input string, it will be rerun on the remaining parts of the string until no more matches are found.
- Parameters
string* — The string to match against the given pattern.
pattern* — The regular expression to match.
options — A JSON object with the following option: convert-numbers - True (default) if text that looks like numeric data should be converted to JSON numbers, false if they should be captured as strings.
- Examples
To extract the key/value pairs ‘a’/1 and ‘b’/2 from the string ‘a=1; b=2’:
;SELECT * FROM regexp_capture_into_json('a=1; b=2', '(\w+)=(\d+)') match_index content 0 {"col_0⋯l_1":1} 1 {"col_0⋯l_1":2}- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
regexp_match(re, str)¶
Match a string against a regular expression and return the capture groups as JSON.
PRQL Name: text.regexp_match
- Parameters
re* — The regular expression to use
str* — The string to test against the regular expression
- Examples
To capture the digits from the string ‘123’:
;SELECT regexp_match('(\d+)', '123') 123To capture a number and word into a JSON object with the properties ‘col_0’ and ‘col_1’:
;SELECT regexp_match('(\d+) (\w+)', '123 four') {"col_0":123,"col_1":"four"}To capture a number and word into a JSON object with the named properties ‘num’ and ‘str’:
;SELECT regexp_match('(?<num>\d+) (?<str>\w+)', '123 four') {"num":123,"str":"four"}- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_replace(str, re, repl), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
regexp_replace(str, re, repl)¶
Replace the parts of a string that match a regular expression.
PRQL Name: text.regexp_replace
- Parameters
str* — The string to perform replacements on
re* — The regular expression to match
repl* — The replacement string. You can reference capture groups with a backslash followed by the number of the group, starting with 1.
- Examples
To replace the word at the start of the string ‘Hello, World!’ with ‘Goodbye’:
;SELECT regexp_replace('Hello, World!', '^(\w+)', 'Goodbye') Goodbye, World!To wrap alphanumeric words with angle brackets:
;SELECT regexp_replace('123 abc', '(\w+)', '<\1>') <123> <abc>- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_match(re, str), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
replace(str, old, replacement)¶
Returns a string formed by substituting the replacement string for every occurrence of the old string in the given string.
- Parameters
str* — The string to perform substitutions on.
old* — The string to be replaced.
replacement* — The string to replace any occurrences of the old string with.
- Examples
To replace the string ‘x’ with ‘z’ in ‘abc’:
;SELECT replace('abc', 'x', 'z') abcTo replace the string ‘a’ with ‘z’ in ‘abc’:
;SELECT replace('abc', 'a', 'z') zbc- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
replicate(str, N)¶
Returns the given string concatenated N times.
- Parameters
str* — The string to replicate.
N* — The number of times to replicate the string.
- Examples
To repeat the string ‘abc’ three times:
;SELECT replicate('abc', 3) abcabcabc- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
reverse(str)¶
Returns the reverse of the given string.
PRQL Name: text.reverse
- Parameters
str* — The string to reverse.
- Examples
To reverse the string ‘abc’:
;SELECT reverse('abc') cba- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
rightstr(str, N)¶
Returns the N rightmost (UTF-8) characters in the given string.
- Parameters
str* — The string to return subset.
N* — The number of characters from the right side of the string to return.
- Examples
To get the last character of the string ‘abc’:
;SELECT rightstr('abc', 1) cTo get the last ten characters of a string, regardless of size:
;SELECT rightstr('abc', 10) abc- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
round(num, [digits])¶
Returns a floating-point value rounded to the given number of digits to the right of the decimal point.
- Parameters
num* — The value to round.
digits — The number of digits to the right of the decimal to round to.
- Examples
To round the number 123.456 to an integer:
;SELECT round(123.456) 123To round the number 123.456 to a precision of 1:
;SELECT round(123.456, 1) 123.5To round the number 123.456 to a precision of 5:
;SELECT round(123.456, 5) 123.456- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), sign(num), square(num), sum(X), total(X)
row_number()¶
Returns the number of the row within the current partition, starting from 1.
- Examples
To number messages from a process:
;SELECT row_number() OVER (PARTITION BY ex_procname ORDER BY log_line) AS msg_num, ex_procname, log_body FROM lnav_example_log msg_num ex_procname log_body 1 gw Goodbye, World! 2 gw Goodbye, World! 3 gw Goodbye, World! 1 hw Hello, World!- See Also
cume_dist(), dense_rank(), first_value(expr), lag(expr, [offset], [default]), last_value(expr), lead(expr, [offset], [default]), nth_value(expr, N), ntile(groups), percent_rank(), rank()
rtrim(str, [chars])¶
Returns a string formed by removing any and all characters that appear in the second argument from the right side of the first.
- Parameters
str* — The string to trim characters from the right side
chars — The characters to trim. Defaults to spaces.
- Examples
To trim the space characters from the end of the string ‘abc ‘:
;SELECT rtrim('abc ') abcTo trim the characters ‘b’ and ‘c’ from the string ‘abbbbcccc’:
;SELECT rtrim('abbbbcccc', 'bc') a- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
shell_exec(cmd, [input], [options])¶
Executes a shell command and returns its output.
PRQL Name: shell.exec
- Parameters
cmd* — The command to execute.
input — A blob of data to write to the command’s standard input.
options — A JSON object containing options for the execution with the following properties:
env — An object containing the environment variables to set or, if NULL, to unset.
See Also
sign(num)¶
Returns the sign of the given number as -1, 0, or 1
- Parameters
num* — The number
- Examples
To get the sign of 10:
;SELECT sign(10) 1To get the sign of 0:
;SELECT sign(0) 0To get the sign of -10:
;SELECT sign(-10) -1- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), square(num), sum(X), total(X)
source_log_stmt(path)¶
A table-valued function for getting information about log statements that were found in source code added by the :add-source-path command.
- Parameters
path* — The source file path
sparkline(value, [upper])¶
Function used to generate a sparkline bar chart. The non-aggregate version converts a single numeric value on a range to a bar chart character. The aggregate version returns a string with a bar character for every numeric input
PRQL Name: text.sparkline
- Parameters
value* — The numeric value to convert
upper — The upper bound of the numeric range. The non-aggregate version defaults to 100. The aggregate version uses the largest value in the inputs.
- Examples
To get the unicode block element for the value 32 in the range of 0-128:
;SELECT sparkline(32, 128) ▂To chart the values in a JSON array:
;SELECT sparkline(value) FROM json_each('[0, 1, 2, 3, 4, 5, 6, 7, 8]') ▁▂▃▄▅▆▇█- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
spooky_hash(str)¶
Compute the hash value for the given arguments.
- Parameters
str — The string to hash
- Examples
To produce a hash for the string ‘Hello, World!’:
;SELECT spooky_hash('Hello, World!') 0b1d52cc5427db4c6a9eed9d3e5700f4To produce a hash for the parameters where one is NULL:
;SELECT spooky_hash('Hello, World!', NULL) c96ee75d48e6ea444fee8af948f6da25To produce a hash for the parameters where one is an empty string:
;SELECT spooky_hash('Hello, World!', '') c96ee75d48e6ea444fee8af948f6da25To produce a hash for the parameters where one is a number:
;SELECT spooky_hash('Hello, World!', 123) f96b3d9c1a19f4394c97a1b79b1880df- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
sqlite_compileoption_get(N)¶
Returns the N-th compile-time option used to build SQLite or NULL if N is out of range.
- Parameters
N* — The option number to get
sqlite_compileoption_used(option)¶
Returns true (1) or false (0) depending on whether or not that compile-time option was used during the build.
- Parameters
option* — The name of the compile-time option.
- Examples
To check if the SQLite library was compiled with ENABLE_FTS3:
;SELECT sqlite_compileoption_used('ENABLE_FTS3') 1
sqlite_source_id()¶
Returns a string that identifies the specific version of the source code that was used to build the SQLite library.
sqlite_version()¶
Returns the version string for the SQLite library that is running.
square(num)¶
Returns the square of the argument
- Parameters
num* — The number to square
- Examples
To get the square of two:
;SELECT square(2) 4- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), sum(X), total(X)
startswith(str, prefix)¶
Test if a string begins with the given prefix
- Parameters
str* — The string to test
prefix* — The prefix to check in the string
- Examples
To test if the string ‘foobar’ starts with ‘foo’:
;SELECT startswith('foobar', 'foo') 1To test if the string ‘foobar’ starts with ‘bar’:
;SELECT startswith('foobar', 'bar') 0- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
strfilter(source, include)¶
Returns the source string with only the characters given in the second parameter
- Parameters
source* — The string to filter
include* — The characters to include in the result
- Examples
To get the ‘b’, ‘c’, and ‘d’ characters from the string ‘abcabc’:
;SELECT strfilter('abcabc', 'bcd') bcbc- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
strftime(format, timestring, modifier)¶
Returns the date formatted according to the format string specified as the first argument.
- Parameters
format* — A format string with substitutions similar to those found in the strftime() standard C library.
timestring* — The string to convert to a date with time.
modifier — A transformation that is applied to the value to the left.
- Examples
To get the year from the timestamp ‘2017-01-02T03:04:05’:
;SELECT strftime('%Y', '2017-01-02T03:04:05') 2017To create a string with the time from the timestamp ‘2017-01-02T03:04:05’ plus one minute:
;SELECT strftime('The time is: %H:%M:%S', '2017-01-02T03:04:05', '+1 minute') The time is: 03:05:05To create a string with the Julian day from the epoch timestamp 1491341842:
;SELECT strftime('Julian day: %J', 1491341842, 'unixepoch') Julian day: 2457848.400949074- See Also
date(timestring, modifier), datetime(timestring, modifier), humanize_duration(secs), julianday(timestring, modifier), time(timestring, modifier), timediff(time1, time2), timeslice(time, slice), timezone(tz, ts)
substr(str, start, [size])¶
Returns a substring of input string X that begins with the Y-th character and which is Z characters long.
- Parameters
str* — The string to extract a substring from.
start* — The index within ‘str’ that is the start of the substring. Indexes begin at 1. A negative value means that the substring is found by counting from the right rather than the left.
size — The size of the substring. If not given, then all characters through the end of the string are returned. If the value is negative, then the characters before the start are returned.
- Examples
To get the substring starting at the second character until the end of the string ‘abc’:
;SELECT substr('abc', 2) bcTo get the substring of size one starting at the second character of the string ‘abc’:
;SELECT substr('abc', 2, 1) bTo get the substring starting at the last character until the end of the string ‘abc’:
;SELECT substr('abc', -1) cTo get the substring starting at the last character and going backwards one step of the string ‘abc’:
;SELECT substr('abc', -1, -1) b- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
sum(X)¶
Returns the sum of the values in the group as an integer.
- Parameters
X* — The values to add.
- Examples
To sum all of the values in the column ‘ex_duration’ from the table ‘lnav_example_log’:
;SELECT sum(ex_duration) FROM lnav_example_log 17- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), total(X)
time(timestring, modifier)¶
Returns the time in this format: HH:MM:SS.
- Parameters
timestring* — The string to convert to a time.
modifier — A transformation that is applied to the value to the left.
- Examples
To get the time portion of the timestamp ‘2017-01-02T03:04:05’:
;SELECT time('2017-01-02T03:04:05') 03:04:05To get the time portion of the timestamp ‘2017-01-02T03:04:05’ plus one minute:
;SELECT time('2017-01-02T03:04:05', '+1 minute') 03:05:05To get the time portion of the epoch timestamp 1491341842:
;SELECT time(1491341842, 'unixepoch') 21:37:22- See Also
date(timestring, modifier), datetime(timestring, modifier), humanize_duration(secs), julianday(timestring, modifier), strftime(format, timestring, modifier), timediff(time1, time2), timeslice(time, slice), timezone(tz, ts)
timediff(time1, time2)¶
Compute the difference between two timestamps in seconds
PRQL Name: time.diff
- Parameters
time1* — The first timestamp
time2* — The timestamp to subtract from the first
- Examples
To get the difference between two timestamps:
;SELECT timediff('2017-02-03T04:05:06', '2017-02-03T04:05:00') 6To get the difference between relative timestamps:
;SELECT timediff('today', 'yesterday') 86400- See Also
date(timestring, modifier), datetime(timestring, modifier), humanize_duration(secs), julianday(timestring, modifier), strftime(format, timestring, modifier), time(timestring, modifier), timeslice(time, slice), timezone(tz, ts)
timeslice(time, slice)¶
Return the start of the slice of time that the given timestamp falls in. If the time falls outside of the slice, NULL is returned.
PRQL Name: time.slice
- Parameters
time* — The timestamp to get the time slice for.
slice* — The size of the time slices
- Examples
To get the timestamp rounded down to the start of the ten minute slice:
;SELECT timeslice('2017-01-01T05:05:00', '10m') 2017-01-01 05:00:00.000000To group log messages into five minute buckets and count them:
;SELECT timeslice(log_time_msecs, '5m') AS slice, count(1)
- FROM lnav_example_log GROUP BY slice
slice count(1)
2017-02⋯.000000 2 2017-02⋯.000000 1 2017-02⋯.000000 1
To group log messages by those before 4:30am and after:
;SELECT timeslice(log_time_msecs, 'before 4:30am') AS slice, count(1) FROM lnav_example_log GROUP BY slice slice count(1) <NULL> 1 2017-02⋯.000000 3- See Also
date(timestring, modifier), datetime(timestring, modifier), humanize_duration(secs), julianday(timestring, modifier), strftime(format, timestring, modifier), time(timestring, modifier), timediff(time1, time2), timezone(tz, ts)
timezone(tz, ts)¶
Convert a timestamp to the given timezone
PRQL Name: time.to_zone
- Parameters
tz* — The target timezone
ts* — The source timestamp
- Examples
To convert a time to America/Los_Angeles:
;SELECT timezone('America/Los_Angeles', '2022-03-02T10:00') 2022-03-02T02:00:00.000000-0800- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), date(timestring, modifier), datetime(timestring, modifier), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), julianday(timestring, modifier), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), strftime(format, timestring, modifier), substr(str, start, [size]), time(timestring, modifier), timediff(time1, time2), timeslice(time, slice), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
total(X)¶
Returns the sum of the values in the group as a floating-point.
- Parameters
X* — The values to add.
- Examples
To total all of the values in the column ‘ex_duration’ from the table ‘lnav_example_log’:
;SELECT total(ex_duration) FROM lnav_example_log 17- See Also
abs(x), acos(num), acosh(num), asin(num), asinh(num), atan2(y, x), atan(num), atanh(num), atn2(y, x), avg(X), ceil(num), degrees(radians), exp(x), floor(num), log10(x), log(x), max(X), min(X), pi(), power(base, exp), radians(degrees), round(num, [digits]), sign(num), square(num), sum(X)
total_changes()¶
Returns the number of row changes caused by INSERT, UPDATE or DELETE statements since the current database connection was opened.
trim(str, [chars])¶
Returns a string formed by removing any and all characters that appear in the second argument from the left and right sides of the first.
- Parameters
str* — The string to trim characters from the left and right sides.
chars — The characters to trim. Defaults to spaces.
- Examples
To trim spaces from the start and end of the string ‘ abc ‘:
;SELECT trim(' abc ') abcTo trim the characters ‘-’ and ‘+’ from the string ‘-+abc+-‘:
;SELECT trim('-+abc+-', '-+') abc- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), unhex(X), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
typeof(X)¶
Returns a string that indicates the datatype of the expression X: “null”, “integer”, “real”, “text”, or “blob”.
- Parameters
X* — The expression to check.
- Examples
To get the type of the number 1:
;SELECT typeof(1) integerTo get the type of the string ‘abc’:
;SELECT typeof('abc') text
unhex(X)¶
Returns a blob value that is a decoding of the given hex string
- Parameters
X* — The hex string to decode
- Examples
To decode the string ‘Hello’ encoded in hex:
;SELECT unhex('48656c6c6f') Hello- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unicode(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
unicode(X)¶
Returns the numeric unicode code point corresponding to the first character of the string X.
- Parameters
X* — The string to examine.
- Examples
To get the unicode code point for the first character of ‘abc’:
;SELECT unicode('abc') 97- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unparse_url(obj), upper(str), xpath(xpath, xmldoc)
unlikely(value)¶
Short-hand for likelihood(X, 0.0625)
- Parameters
value* — The boolean value to return
unparse_url(obj)¶
Convert a JSON object containing the parts of a URL into a URL string
- Parameters
obj* — The JSON object containing the URL parts
- Examples
To unparse the object ‘{“scheme”: “https”, “host”: “example.com”}’:
;SELECT unparse_url('{"scheme": "https", "host": "example.com"}') https://example.com/- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), upper(str), xpath(xpath, xmldoc)
upper(str)¶
Returns a copy of the given string with all ASCII characters converted to upper case.
- Parameters
str* — The string to convert.
- Examples
To uppercase the string ‘aBc’:
;SELECT upper('aBc') ABC- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), xpath(xpath, xmldoc)
xpath(xpath, xmldoc)¶
A table-valued function that executes an xpath expression over an XML string and returns the selected values.
- Parameters
xpath* — The XPATH expression to evaluate over the XML document.
xmldoc* — The XML document as a string.
- Examples
To select the XML nodes on the path ‘/abc/def’:
;SELECT * FROM xpath('/abc/def', '<abc><def a="b">Hello</def><def>Bye</def></abc>') result node_path node_attr node_text <def a=⋯</def>␊ /abc/def[1] {"a":"b"} Hello <def>Bye</def>␊ /abc/def[2] {} ByeTo select all ‘a’ attributes on the path ‘/abc/def’:
;SELECT * FROM xpath('/abc/def/@a', '<abc><def a="b">Hello</def><def>Bye</def></abc>') result node_path node_attr node_text b /abc/def[1]/@a {"a":"b"} HelloTo select the text nodes on the path ‘/abc/def’:
;SELECT * FROM xpath('/abc/def/text()', '<abc><def a="b">Hello ★</def></abc>') result node_path node_attr node_text Hello ★ /abc/def/text() {} Hello ★- See Also
anonymize(value), char(X), charindex(needle, haystack, [start]), concat_ws(sep, X), concat(X), decode(value, algorithm), encode(value, algorithm), endswith(str, suffix), extract(str), fuzzy_match(pattern, str), group_concat(X, [sep]), group_spooky_hash(str), gunzip(b), gzip(value), humanize_duration(secs), humanize_file_size(value), humanize_id(id), instr(haystack, needle), leftstr(str, N), length(str), logfmt2json(str), lower(str), ltrim(str, [chars]), padc(str, len), padl(str, len), padr(str, len), parse_url(url), pretty_print(str), printf(format, X), proper(str), regexp_capture_into_json(string, pattern, [options]), regexp_capture(string, pattern), regexp_match(re, str), regexp_replace(str, re, repl), replace(str, old, replacement), replicate(str, N), reverse(str), rightstr(str, N), rtrim(str, [chars]), sparkline(value, [upper]), spooky_hash(str), startswith(str, prefix), strfilter(source, include), substr(str, start, [size]), timezone(tz, ts), trim(str, [chars]), unhex(X), unicode(X), unparse_url(obj), upper(str)
yaml_to_json(yaml)¶
Convert a YAML document to a JSON-encoded string
PRQL Name: yaml.to_json
- Parameters
yaml* — The YAML value to convert to JSON.
- Examples
To convert the document “abc: def”:
;SELECT yaml_to_json('abc: def') {"abc": "def"}- See Also
jget(json, ptr, [default]), json_array_length(X, [P]), json_array(X), json_concat(json, value), json_contains(json, value), json_each(X, [P]), json_extract(X, P), json_group_array(value), json_group_object(name, value), json_insert(X, P, Y), json_object(N, V), json_quote(X), json_remove(X, P), json_replace(X, P, Y), json_set(X, P, Y), json_tree(X, [P]), json_type(X, [P]), json_valid(X), json(X)
zeroblob(N)¶
Returns a BLOB consisting of N bytes of 0x00.
- Parameters
N* — The size of the BLOB.
;.dump path table¶
Dump one or more tables to a file as a series of SQL statements
- Parameters
path* — The path to the file to write
table — The name of the table to dump
- See Also
:append-to path, ;.read path, ;.save path, :echo [-n] msg, echoln(value), :export-session-to path, :open [–since] [–until] path, :pipe-line-to shell-cmd, :pipe-to shell-cmd, :redirect-to [path], :write-csv-to [–anonymize] path, :write-json-cols-to [–anonymize] path, :write-json-to [–anonymize] path, :write-jsonlines-to [–all] [–anonymize] path, :write-raw-to [–view] [–anonymize] path, :write-screen-to [–anonymize] path, :write-table-to [–anonymize] path, :write-to [–anonymize] path, :write-view-to [–anonymize] path, :xopen path
;.msgformats¶
Executes a query that will summarize the different message formats found in the logs
;.read path¶
Execute the SQLite statements in the given file
- Parameters
path* — The path to the file to write
- See Also
:append-to path, ;.dump path table, ;.save path, :echo [-n] msg, echoln(value), :export-session-to path, :open [–since] [–until] path, :pipe-line-to shell-cmd, :pipe-to shell-cmd, :redirect-to [path], :write-csv-to [–anonymize] path, :write-json-cols-to [–anonymize] path, :write-json-to [–anonymize] path, :write-jsonlines-to [–all] [–anonymize] path, :write-raw-to [–view] [–anonymize] path, :write-screen-to [–anonymize] path, :write-table-to [–anonymize] path, :write-to [–anonymize] path, :write-view-to [–anonymize] path, :xopen path
;.save path¶
Save the current database to a SQLite file
- Parameters
path* — The path to the file to write
- See Also
:append-to path, ;.dump path table, ;.read path, :echo [-n] msg, echoln(value), :export-session-to path, :open [–since] [–until] path, :pipe-line-to shell-cmd, :pipe-to shell-cmd, :redirect-to [path], :write-csv-to [–anonymize] path, :write-json-cols-to [–anonymize] path, :write-json-to [–anonymize] path, :write-jsonlines-to [–all] [–anonymize] path, :write-raw-to [–view] [–anonymize] path, :write-screen-to [–anonymize] path, :write-table-to [–anonymize] path, :write-to [–anonymize] path, :write-view-to [–anonymize] path, :xopen path
;.schema name¶
Switch to the SCHEMA view that contains a dump of the current database schema
- Parameters
name* — The name of a table to jump to
aggregate expr¶
PRQL transform to summarize many rows into one
- Parameters
expr* — The aggregate expression(s)
- Examples
To group values into a JSON array:
;from [{a=1}, {a=2}] | aggregate { arr = json.group_array a } [1,2]- See Also
append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
append table¶
PRQL transform to concatenate tables together
- Parameters
table* — The table to use as a source
- See Also
aggregate expr, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
derive column¶
PRQL transform to derive one or more columns
- Parameters
column* — The new column
- Examples
To add a column that is a multiplication of another:
;from [{a=1}, {a=2}] | derive b = a * 2 a b 1 2 2 4- See Also
aggregate expr, append table, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
filter expr¶
PRQL transform to pick rows based on their values
- Parameters
expr* — The expression to evaluate over each row
- Examples
To pick rows where ‘a’ is greater than one:
;from [{a=1}, {a=2}] | filter a > 1 2- See Also
aggregate expr, append table, derive column, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
from table¶
PRQL command to specify a data source
- Parameters
table* — The table to use as a source
- Examples
To pull data from the ‘http_status_codes’ database table:
;from http_status_codes | take 3 status message 100 Continue 101 Switchi⋯otocols 102 ProcessingTo use an array literal as a source:
;from [{ col1=1, col2='abc' }, { col1=2, col2='def' }] col1 col2 1 abc 2 def- See Also
aggregate expr, append table, derive column, filter expr, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
group key_columns pipeline¶
PRQL transform to partition rows into groups
- Parameters
key_columns* — The columns that define the group
pipeline* — The pipeline to execute over a group
- Examples
To group by log_level and count the rows in each partition:
;from lnav_example_log | group { log_level } (aggregate { count this }) log_level COUNT(*) debug 1 info 1 warn 1 error 1- See Also
aggregate expr, append table, derive column, filter expr, from table, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
join [side:inner] table condition¶
PRQL transform to add columns from another table
- Parameters
side — Specifies which rows to include
table* — The other table to join with the current rows
condition* — The condition used to join rows
- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
select expr¶
PRQL transform to pick and compute columns
- Parameters
expr* — The columns to include in the result set
- Examples
To pick the ‘b’ column from the rows:
;from [{a=1, b='abc'}, {a=2, b='def'}] | select b b abc defTo compute a new column from an input:
;from [{a=1}, {a=2}] | select b = a * 2 b 2 4- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
sort expr¶
PRQL transform to sort rows
- Parameters
expr* — The values to use when ordering the result set
- Examples
To sort the rows in descending order:
;from [{a=1}, {a=2}] | sort {-a} a 2 1- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
stats.average_of col¶
Compute the average of col
- Parameters
col* — The column to average
- Examples
To get the average of a:
;from [{a=1}, {a=1}, {a=2}] | stats.average_of a 1.3333333333333333- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
stats.by col values¶
A shorthand for grouping and aggregating
- Parameters
col* — The column to sum
values* — The aggregations to perform
- Examples
To partition by a and get the sum of b:
;from [{a=1, b=1}, {a=1, b=1}, {a=2, b=1}] | stats.by a {sum b} a COALESC⋯(b), 0) 1 2 2 1- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
stats.count_by column¶
Partition rows and count the number of rows in each partition
- Parameters
column — The columns to group by
- Examples
To count rows for a particular value of column ‘a’:
;from [{a=1}, {a=1}, {a=2}] | stats.count_by a a total 1 2 2 1- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
stats.hist col [slice:’1h’] [top:10]¶
Count the top values per bucket of time
- Parameters
col* — The column to count
slice — The time slice
top — The limit on the number of values to report
- Examples
To chart the values of ex_procname over time:
;from lnav_example_log | stats.hist ex_procname tslice v 2017-02⋯.000000 {"gw":3,"hw":1}To chart the values of ex_procname for every second:
;from lnav_example_log | stats.hist ex_procname slice:'1s' tslice v 2017-02⋯.000000 {"gw":1,"hw":1} 2017-02⋯.000000 {"gw":1} 2017-02⋯.000000 {"gw":1}- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.sum_of col, utils.distinct col
stats.sum_of col¶
Compute the sum of col
- Parameters
col* — The column to sum
- Examples
To get the sum of a:
;from [{a=1}, {a=1}, {a=2}] | stats.sum_of a 4- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], utils.distinct col
take n_or_range¶
PRQL command to pick rows based on their position
- Parameters
n_or_range* — The number of rows or range
- Examples
To pick the first row:
;from [{a=1}, {a=2}, {a=3}] | take 1 1To pick the second and third rows:
;from [{a=1}, {a=2}, {a=3}] | take 2..3 a 2 3- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col, utils.distinct col
utils.distinct col¶
A shorthand for getting distinct values of col
- Parameters
col* — The column to sum
- Examples
To get the distinct values of a:
;from [{a=1}, {a=1}, {a=2}] | utils.distinct a a 1 2- See Also
aggregate expr, append table, derive column, filter expr, from table, group key_columns pipeline, join [side:inner] table condition, select expr, sort expr, take n_or_range, stats.average_of col, stats.by col values, stats.count_by column, stats.hist col [slice:’1h’] [top:10], stats.sum_of col